
While I try to minimize Politics and Economics as much as I can on this blog, it sometimes surfaces. It is possible that some people may benefit or at least be aware.
A bit of background is necessary before I jump into the intricacies of the Maharashtra Real Estate Rules and Regulation Draft Rules 2016 (RERA) .
Since ever, but more prominently since 2007/8 potential homeowners from across the country have been suffering at the hands of the builder/promoter for number of years. While it would be wrong to paint all the Real Estate Developers and Builders as cheats (we as in all tenants and homeowners hope there are good ones out there) many Real Estate Builders and promoters have cheated homeowners of their hard-earned money. This has also lessened the secondary (resale) market and tenants like me have to fight over morsels as supply is tight.
There were two broad ways in which the cheating is/was done
a. Take deposits and run away i.e. fly by night operators Here the only option for a homeowner is to file an FIR (First Information Report) and hope the culprits are caught. 99% of the time the builder/promoter goes somewhere abroad and the potential home buyers/home-owners are left holding the can. This is usually done by small real estate promoters and builders.
b. The big boys would take all or most money of the project, may register or not register the flat in your name, either build a quarter or half-finished building and then make excuses. There are some who do not even build. The money given is used by the builder/developer either for his own needs or using that money in some high-profile project which is expensive and may have huge returns. They know that home-owners can t do anything, at the most go to the court which will take more than a decade or two during which time the developer would have interest-free income and do whatever he wants to do.
One of the bigger stories which came up this year was when the Indian Cricket Captain, M.S. Dhoni (cricket is a religion in India, and the cricketers gods for millions of Indians) had to end his brand engagement and ambassadorship from Amrapali Housing Group. Apparently, his wife Sakshi was on the Board of directors at Amrapali Housing and had to
resign
The Government knew of such issues and had been working since last few years. Under the present Government, a Model Agreement and a Model Real Estate Rules and Regulation Bill was
passed on 31st March and came into force on 1st May 2016.
India, similar to the U.S. and U.K. follows a federal structure. While I have shared this before, most of the laws in India fall in either of three lists, Central List, Concurrent Lists and State Lists. Housing for instance, is a state subject so any laws concerning housing has to be made by the state legislature.
Having a statutory requirement to put the bill in 6 months from 1st of May, the Government of Maharashtra chose to put the draft rules in public domain on 12th December 2016, about 10 days ago and there were efforts to let it remain low-key so people do not object as we are still in the throes of demonetisation. By law they should have given 30 days for people to raise objections and give suggestions.
The State Government too could have easily asked an extension and as both the State and the Centre are of the same Political Party they would have easily got it.
With that, below is the e-mail I sent to suggesstionsonrera@maharashtra.gov.in
Sub Some suggestions for RERA biggest suggestion, need to give more time study the implications for house-owners.
Respected Sir/Madame,
I will be publishing the below mail as a public letter on my blog as well.
I am writing as a citizen, a voter, a potential home owner, currently a tenant . If houses supply is not in time, it is us, the tenants who have the most to lose as we have to fight over whatever is in the market. I do also hope to be a home buyer at some point in time so these rules would affect me also somewhere in the hazy future.
I came to know through the media that Maharashtra Govt. recently introduced draft rules for RERA Real Estate (Regulation and Development) Act, 2016 . I hope to impress upon you that these proposed Rules and Regulations need to be thoroughly revised and new draft rules shared with the public at large with proper announcement in all newspapers and proper time ( more than a month ) to study and give replies on the said matter.
My suggestions and complaints are as under
a. The first complaint and suggestion is that the date between the draft regulations and suggestions being invited by members of public is and was too little 12 December 2016 23 December 2016 (only 11 days) for almost 90 pages of Government rules and regulations which needs multiple rounds of re-reading to understand the implications of the draft rules .
Add to that unlike the Central Building Legislation, Model Agreement which was prepared by Centre and also given wide publicity, the Maharashtra Govt. didn t do any such publicity to bring it to the
notice of the people.
b. I ask where was the hurry to publish these draft rules now when everybody is suffering through the result of cash-crunch on top of other things. If the said draft rules were put up in January 2017, I am sure more people would have responded to the draft rules. Ir raises suspicion in the mind of everybody the timing of sharing the draft rules and the limited time given to people to respond.
E.g. When TRAI (Telephone Regulatory Authority of India) asked for suggestion it gives more than a month, and something like housing which is an existential question for everybody, i.e. the poor, the middle and the rich, you have given pretty less time. While I could change my telephone service providers at a moment s notice without huge loss, the same cannot be said either for a house owner (in case of builder) or a tenant as well. This is just not done.
c. The documents are at
https://housing.maharashtra.gov.in/sitemap/housing/Rera_rules.htm under different sub-headings while the correct structure of the documents can be found at nared s site
http://naredco.in/notifications.asp . At the very least, the documents should have been in proper order.
Coming to some of the salient points raised both in the media and elsewhere
1. On page 6 of Part IV-A Ext1.pdf you have written
Explanation.-The registration of a real estate project shall not be required,-
(i) for the purpose of any renovations or repair or redevelopment which does not involve marketing, advertisement, selling or new allotment of any apartment , plot or building as the case may be under
the real estate project; RERA draft rules
What it means is that the house owner and by the same stroke the tenant would have absolutely no voice to oppose any changes made to the structure at any point of time after the building is built. This means the builder is free to build 12-14-16 even 20 stories building when the original plans were for 6-8-10. This rule gives the builder to do free for all till the building doesn t get converted into a society, a process which does and can take years to happen.
2. A builder has to take innumerable permissions from different authorities at each and every stage till possession of a said property isn t handed over to a home buyer and by its extension to the tenant. Now any one of these authorities could sit on the papers and there is no accountability of by when papers would be passed under a competent authority s desk. There was a wide belief that there would be some
rules and regulations framed in this regard but the draft rules are silent on the subject matter.
3. In Draft rule 5. page 8 of Part IV-A Ext1.pdf you write
Withdrawal of amounts deposited in separate account.-(1) With regard to the withdrawal of amounts deposited under sub-clause (D) of clause (l) of sub-section (2) of section 4, the following provisions shall apply:-
(i) For new projects which will be registered after commencement.
Deposit in the escrow account is from now onwards. So what happens to the projects which are ongoing at the moment, either at the registration stage or at building stage, thousands of potential house owners would be left to fend for themselves. There needs to be some recourse for them as well.
3b. Another suggestion is that the house-owners are duly informed when promoters/builders are taking money from the bank and should have the authority to see that proper documents and procedure was followed. It is possible that unscrupulous elements may either bypass it or give some different documents which are not in knowledge of the house-owner, thus defeating the purpose of the escrow account itself.
4. On page 44 of Pt.IV-A Ext.161 in the Model Agreement to be entered
between the Promoter and the Alottee you have mentioned
(i)The Allottee hereby agrees to purchase from the Promoter and the Promoter hereby agrees to sell to the Allottee one Apartment No. .. of the type .. of carpet area admeasuring .. sq. metres on floor in the building __________along with (hereinafter referred to as the Apartment ) as shown in the Floor plan thereof hereto annexed and marked Annexures C
for the consideration of Rs. . including Rs. . being the proportionate price of the common areas and facilities appurtenant to the premises, the nature, extent and description of the common/limited common areas and facilities which are more particularly described in the Second Schedule annexed herewith. (the price of the Apartment including the proportionate price of the limited common areas and facilities and parking spaces should be shown separately).
(ii) The Allottee hereby agrees to purchase from the Promoter and the Promoter hereby agrees to sell to the Allottee garage bearing Nos ____ situated at _______ Basement and/or stilt and /or ____podium being
constructed in the layout for the consideration of Rs. ____________/-
(iii) The Allottee hereby agrees to purchase from the Promoter and the Promoter hereby agrees to sell to the Allottee Car parking spaces bearing Nos ____ situated at _______ Basement and/or stilt and /or ____podium and/or open parking space, being constructed in the layout for the
consideration of Rs. ____________/-.
The total aggregate consideration amount for the apartment including garages/car parking spaces is
thus Rs.______/- Draft rules.
What has been done here is the parking space has been divorced from sale of the flat . It is against natural justice, logic, common sense as well-known precedents in jurisprudence (i.e. law)
In September 2010, the bench of Justices R M Lodha and A K Patnaik had ruled in a judgement stating developers cannot sell parking spaces as independent real-estate units. The court ruled that parking areas are common areas and facilities . This was on behalf of a precedent in Mumbai High Court as well.
http://www.reinventingparking.org/2010/09/important-parking-ruling-by-indias.html
This has been reiterated again and again in courts as well as consumer
forums
http://timesofindia.indiatimes.com/city/mumbai/Cant-charge-flat-buyer-extra-for-parking-slot/articleshow/22475233.cms
and has been the norm in several Apartment Acts over multiple states
http://apartmentadda.com/blog/2015/02/19/rules-pertaining-to-parking-spaces-in-apartment-complexes/
5. In case of dispute, the case will high court which is inundated by huge number of pending cases.
As recently as August 2016 there was a news item in Indian Express which talks about the spike in pending cases. Putting a case in the high court will weigh heavily on the homeowner, financially and
mentally
http://indianexpress.com/article/cities/mumbai/more-cases-and-increased-staff-strength-putting-pressure-on-bombay-high-court-building-2964796/
It may be better to use the services of National Consumer Disputes Redressal Commission'(NCDRC) where there is possibility of quicker justice and quick resolution. There is possibility of group actions taking place which will reduce duplicity of work on behalf of the petitioners.
6. There is neither any clarity, incentive or punitive action against the promoter/builder if s/he delay conveyance to the society in order to get any future developmental and FSI rights. To delay handing over conveyance, the builders delay completion of the last building in a said project. there should be both a compensatory and punitive actions taken against the builder if he is unable to prove any genuine cause for the same.
7. There needs to be the provision with regard to need for developers to make public disclosures pertaining to building approvals. This while I had shared above needs to be explicitly mentioned so house-owners know the promoter/builder are on the right path.
8. There needs to be a provision that prohibits refusal to sell property to any person on the basis of his/her religion, marital status or dietary preferences.
9. There is lot of ambiguity if criminal proceedings can be initiated against a promoter/developer if s/he fails to deliver the flat on time.
The developer should be criminally liable if he doesn t give the flat with all the amenities, fixtures and anything which was on agreement signed by both parties and for which the payment has been given in
full at time of possession of a flat.
10. Penalties for the promoter/builder is capped at 10% in case of any wrong-doing. Apart from proving the charge, the onus of which would lie on the house-owner, capping it at 10% is similar to
A teacher telling a naughty student, do whatever you want to do, I am only going to hit you 5 times.
Such a drafting encourages the Promoter/builder to play mischief. The builder knows his exposure is pretty limited. Liability is limited so he will try to get with whatever he can. Having a high penalty clause will deter him.
11. There was talk and shown in the Center s model agreement the precedent of providing names, addresses and contact details of other allot-tees or home-owners of a building that would have multiple dwelling units . This is nowhere either in the agreement or mentioned anywhere else in the four documents.
12. An addition to the above would be that the details provided should be correct and updated as per the records maintained by the Promoter/builder.
13. Today, there is no way for a potential house-owner to know if the builder had broken any norms or has any cases in court pending against him. There should be a way for the potential house-owner to find out.
14. A builder can terminate a flat purchase agreement by giving just a week s notice on email to the buyer who defaults on an instalment. But the developer can refund the money without interest to the
purchaser at leisure, within six months.Under MOFA (the earlier rules), the developer could cancel the agreement after giving a 15 days notice, and the builder could resell the flat only after refunding money to the original buyer. Under the new draft rules, a builder can immediately sell the flat after terminating the agreement.
15. The new draft rules say a buyer must pay 30% of the total cost while signing the agreement and 45% when the plinth of the building is constructed. The earlier state law stipulated 20% payment when the
agreement is signed with the developer.
16. The Central model agreement and rules proposed a fee of INR Rs 1,000 for filing complaints before housing authority; the state draft has proposed to hike this fee to Rs INR Rs. 10,000/-
17. Reading the Central Model Agreement, key disclosures under Section 4 (2)and Rule 3 (2) of the Central Model Rules have been excluded to be put up on the website of the Authority. These included carpet area of flat, encumbrance certificate (this would have disclosed encumbrances in respect of the land where the real estate project is proposed to be undertaken), copy of the legal title report and sanctioned plan of the building.
Due to this house-owner would always be in dark and assume that everything is alright.
There have been multiple instances of this over years
Some examples
http://www.deccanchronicle.com/140920/nation-current-affairs/article/builder-encroaches-%E2%80%98raja-kaluve%E2%80%99
http://indianexpress.com/article/cities/ahmedabad/surat-builder-grabs-tribal-land-using-fake-documents/
http://www.thehindu.com/news/cities/bangalore/bmtf-books-exmayor-wife-for-grabbing-ca-site/article7397062.ece
http://timesofindia.indiatimes.com/city/thane/24-acre-ambernath-plot-usurped-with-fake-docus/articleshow/55654139.cms
18. The Central rule requires a builder to submit an annual report including profit and loss account, balance sheet, cash flow statement, directors report and auditors report for the preceding three financial years, among other things. However, the Maharashtra draft rules are silent on such a requirement.
While the above is what I could perceive in the limited amount I came to know. This should be enough to convince that more needs to be done from the house-owner s side.
Update Just saw Quint s
Op-Ed goes in more detail.
Filed under:
Miscellenous Tagged:
#Draft Rules for Real Estate Rules and Regulation (2016),
#hurry,
#Name,
#Response,
Amrapali Group,
Contact details of other hom-owners in a scheme.,
M.S. Dhoni 






 Recently Vincent Bernat wrote about writing his own simple terminal, using
Recently Vincent Bernat wrote about writing his own simple terminal, using  I was an happy user of
I was an happy user of 


 Something I was used to and which came as standard on wheezy if you installed acpi-support was screen locking when you where suspending, hibernating, ... This is something that I still haven't found on Jessie and which somebody had point me to solve via /lib/systemd/system-sleep/whatever hacking, but that didn't seem quite right, so I gave it a look again and this time I was able to add some config files at /etc/systemd and then a script which does what acpi-support used to do before Edit: Michael Biebl has sugested on my google+ post that this is an ugly hack and that one shouldn't use this solution and instead what we should use are solutions with direct support for logind like desktops with built in support or xss-lock, the reasons for this being ugly are pointed at
Something I was used to and which came as standard on wheezy if you installed acpi-support was screen locking when you where suspending, hibernating, ... This is something that I still haven't found on Jessie and which somebody had point me to solve via /lib/systemd/system-sleep/whatever hacking, but that didn't seem quite right, so I gave it a look again and this time I was able to add some config files at /etc/systemd and then a script which does what acpi-support used to do before Edit: Michael Biebl has sugested on my google+ post that this is an ugly hack and that one shouldn't use this solution and instead what we should use are solutions with direct support for logind like desktops with built in support or xss-lock, the reasons for this being ugly are pointed at  I attended this year's Linux Kernel Summit in Santa Fe, NM, USA and
made notes on some of the sessions that were relevant to Debian.
I attended this year's Linux Kernel Summit in Santa Fe, NM, USA and
made notes on some of the sessions that were relevant to Debian.
 Previously:
Previously: 
 Here is my monthly update covering a large part of what I have been doing in the free software world (
Here is my monthly update covering a large part of what I have been doing in the free software world ( What happened in the
What happened in the 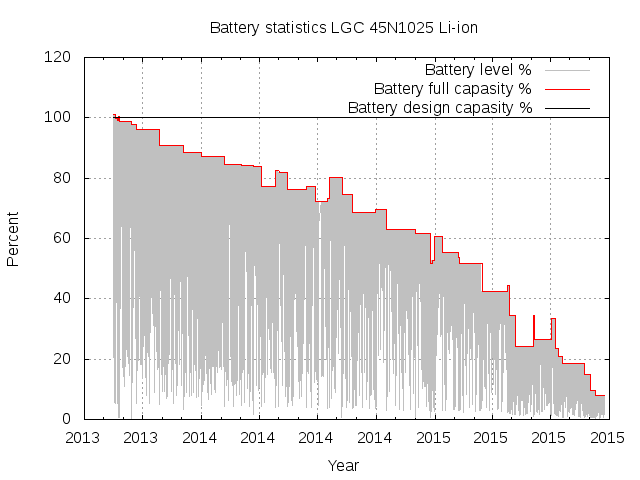 First I tried to find a sensible Debian package to record the
battery status, assuming that this must be a problem already handled
by someone else. I found
First I tried to find a sensible Debian package to record the
battery status, assuming that this must be a problem already handled
by someone else. I found


 I get quite a bit of recruitment spam, especially via my
I get quite a bit of recruitment spam, especially via my  The random gaps (
The random gaps ( With a
With a {kind=link}